





Martin Splitt is back again on the Google Webmasters YouTube channel, and this time he’s cracking SEO myths related to the elusive Googlebot. In the previous video, he explained the basics of SEO (check out our summary of this episode here!) but this week’s episode delves a little deeper into the technicalities associated with search engine optimization. But as always, Splitt makes his narrative accessible to everyone, so it’s still worth watching even if you’re an SEO newbie. But if you don’t have time to watch, no fear: we’re summarizing the most important points here.

This time around Splitt is talking with Suz Hinton, a Senior Software Engineer at Microsoft who is also part of the Global Cloud Advocate team. In their conversation they discuss and answer the following questions and SEO topics:
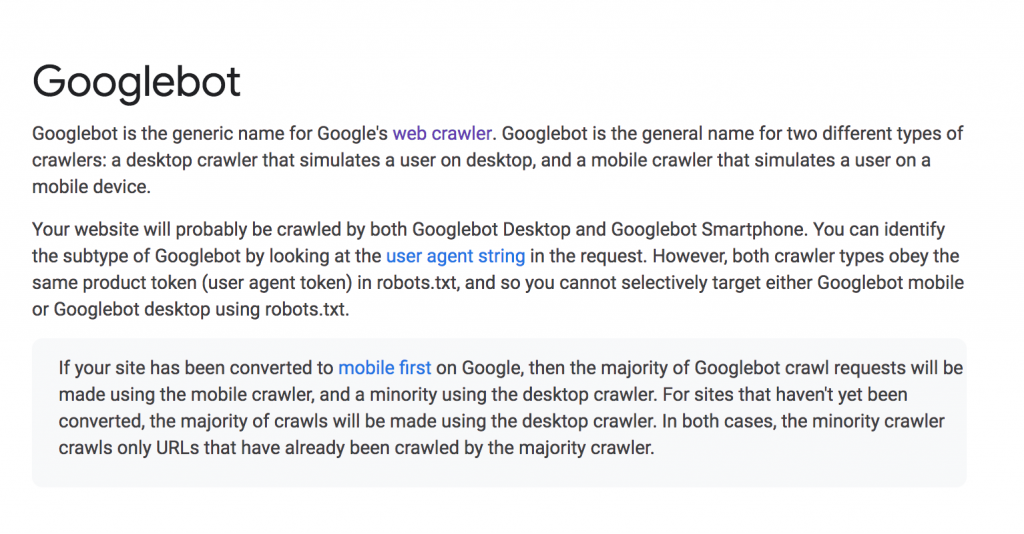
What is – and what is not – Googlebot (crawling, indexing, ranking)?
Does Googlebot behave like a web browser?
How often does Googlebot crawl, how much does it crawl, and how much can a server bear?
Crawlers & JavaScript-based websites
How do you tell that it’s Googlebot visiting your site?
The difference between mobile-first indexing and mobile friendliness
Quality indicators for ranking
There’s a lot of confusion related to SEO because people have a hard time understanding how the Googlebot actually works. This video seeks to change that.
So what is – and what is not – Googlebot (crawling, indexing, ranking)?
Googlebot is a program run by Google that basically does 3 things: It crawls, indexes, and ranks (although it doesn’t rank as much as it used to).
It grabs the content from the internet, figures out what the content is about, and decides what content is the best for each particular query. The ranking aspect is informed by Googlebot, but is not actually part of it.
Does Googlebot behave like a web browser?
In the beginning it does; the crawling aspect is when the bot ends up on your page either by following a link, because you submitted a site map, or because you used search console and asked Googlebot to reindex your site (this triggers a crawl).
How often does Googlebot crawl, how much does it crawl, and how much can a server bear?
Google indexes content and when it does, it understand what type of content it is and what it is about. It uses this information to determine how often it needs to crawl your site. Using Splitt’s example, if it’s a newspaper website Googlebot knows the information will probably change daily and so it will crawl the site more often than say a retail website where the content probably only changes weekly or monthly.
Googlebot uses what they call the “crawl budget” to see how much your server can bear when crawling. This means that they crawl a little bit, then ramp it up to a little bit more until they start seeing errors, and then they back off. It’s very much trial and error, and they try not to overload your site, but it does happen. If necessary, you can use Google Search Console to ask them to tone down the crawling if you’re seeing a negative impact on your server. The more links and pages and images and videos you have embedded into your site, the more Googlebot is going to crawl, and the more strain that could potentially put on your website.
 Crawlers & JavaScript-based websites
Crawlers & JavaScript-based websites
Many websites use JavaScript, and a common (but untrue) SEO myth is that Googlebot doesn’t crawl Javascript sites. This is incorrect. Googlebot WILL crawl your site if it’s built with Javascript, it’s just deferred, so it happens at a later point than websites that don’t use Java. The video explains more in depth the reasoning why it takes longer to crawl Javascript sites, but the moral of the story here is that if you want your site to be indexed quickly, don’t use Java. If you’re fine waiting through the rendering process, then using Java won’t be a problem. More on Javascript and SEO in the next episode of SEO mythbusters.
How do you tell that it’s Googlebot visiting your site?

They have a specific string they send you that says they’re a robot- it’s a user agent header that has the word “Googlebot” in it. Pretty straightforward. If you notice it’s Googlebot request access to your site, Splitt recommends sending it a pre-rendered static HTML in order to cut down on crawling time and reduce the strain put on your website. This is called “dynamic rendering”.
The difference between mobile-first indexing and mobile friendliness
Mobile first indexing is about Google discovering your content using a mobile user agent (it will say this in the user-agent heading so you know it’s the mobile Googlebot). The purpose of mobile first indexing is about getting your mobile content into the index instead of the desktop content.
Mobile friendliness refers to how user-friendly your website is for mobile devices, ie: how big are your tap targets, does everything fit within your viewport, etc. Googlebot is looking at the quality of your content here as opposed to just whether or not it’s mobile content vs. desktop.
Quality indicators for ranking
Google has over 200 signals that contribute to their ranking factors, and so manipulating one or two might get you a better ranking for a specific query, but it will hurt your ranking for other queries more. Link-building is one signal. Keyword research is another. SEO companies promise people improved rankings by focusing on specific signals because it’s an easier solution then asking clients to strategically determine who their audience is, what are they looking for, and how can you provide it to then. Additionally, these signals are constantly moving and changing so even if you figure out how to beat the system once, it won’t be a long-term strategy. And ultimately, if you try to take a short cut you’ll lose. Splitt recommends not trying to “play the game”, and instead just “build good content for the users and you’ll be fine.”
What do you think about this second episode of SEO Mythbusters? Did you successfully have some myths debunked, or is Googlebot still as confusing as ever? If you want more information, watch the YouTube video here. On the next episode of SEO Mythbusting 101, Splitt will sit down with Jamie Alberico to discuss SEO and JavaScript and whether or not they will ever be friends.
feature image credit: sitechecker.pro
image 1: linkedin.com
image 2: support.google.com
image 3: javascript.com
image 4: support.google.com
